Of lakes and sparks – How Hadoop 2 got it right
Misconceptions

Hadoop version 2 has transitioned from an application to a Big Data platform. Reports of its demise are premature at best.
In a recent story on the PCWorld website titled "Hadoop successor sparks a data analysis evolution," the author predicts that Apache Spark will supplant Hadoop in 2015 for Big Data processing [1]. The article is so full of mis- (or dis-)information that it really is a disservice to the industry. To provide an accurate picture of Spark and Hadoop, several topics need to be explored in detail.
First, like any article on "Big Data," is it important to define exactly what you are talking about. The term "Big Data" is a marketing buzz-phase that has as much meaning as things like "Tall Mountain" or "Fast Car." Second, the concept of the data lake (less of a buzz-phrase and more descriptive than Big Data) needs to be defined. Third, Hadoop version 2 is more than a MapReduce engine. Indeed, if there is anything to take away from this article it is the message in Figure 1. And, finally, how Apache Spark neatly fits into the Hadoop ecosystem will be explained.
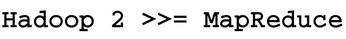
[...]
Buy this article as PDF
(incl. VAT)
Buy Linux Magazine
US / Canada
UK / Australia
Subscribe to our Linux Newsletters
Find Linux and Open Source Jobs
Subscribe to our ADMIN Newsletters
Support Our Work
Linux Magazine content is made possible with support from readers like you. Please consider contributing when you’ve found an article to be beneficial.

News
-
Ubuntu 25.04 Coming Soon
Ubuntu 25.04 (Plucky Puffin) has been given an April release date with many notable updates.
-
Gnome Developers Consider Dropping RPM Support
In a move that might shock a lot of users, the Gnome development team has proposed the idea of going straight up Flatpak.
-
openSUSE Tumbleweed Ditches AppArmor for SELinux
If you're an openSUSE Tumbleweed user, you can expect a major change to the distribution.
-
Plasma 6.3 Now Available
Plasma desktop v6.3 has a couple of pretty nifty tricks up its sleeve.
-
LibreOffice 25.2 Has Arrived
If you've been hoping for a release that offers more UI customizations, you're in for a treat.
-
TuxCare Has a Big AlmaLinux 9 Announcement in Store
TuxCare announced it has successfully completed a Security Technical Implementation Guide for AlmaLinux OS 9.
-
First Release Candidate for Linux Kernel 6.14 Now Available
Linus Torvalds has officially released the first release candidate for kernel 6.14 and it includes over 500,000 lines of modified code, making for a small release.
-
System76 Refreshes Meerkat Mini PC
If you're looking for a small form factor PC powered by Linux, System76 has exactly what you need in the Meerkat mini PC.
-
Gnome 48 Alpha Ready for Testing
The latest Gnome desktop alpha is now available with plenty of new features and improvements.
-
Wine 10 Includes Plenty to Excite Users
With its latest release, Wine has the usual crop of bug fixes and improvements, along with some exciting new features.