Car NOT Goat
Programming Snapshot – Neural Networks

© Lead Image © Frantisek Hojdysz, 123RF.com
The well-known Monty Hall game show problem can be a rewarding maiden voyage for prospective statisticians. But is it possible to teach a neural network to choose between goats and cars with a few practice sessions?
Here's the problem: In a game show, a candidate has to choose from three closed doors; waiting behind these doors is a car, which is the main prize, a goat, and yet another goat (Figure 1). The candidate first picks a door, and then the presenter opens another, behind which there is a bleating goat. How is the candidate most likely to win the grand prize: Sticking with their choice or switching to the remaining closed door?
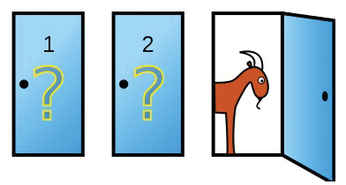
As has been shown [1] [2], the candidate is better off switching, because then they double their chances of winning. But how does a neural network learn the optimal game strategy while being rewarded for wins and punished for losses?
[...]
Buy this article as PDF
(incl. VAT)
Buy Linux Magazine
Subscribe to our Linux Newsletters
Find Linux and Open Source Jobs
Subscribe to our ADMIN Newsletters
Support Our Work
Linux Magazine content is made possible with support from readers like you. Please consider contributing when you’ve found an article to be beneficial.

News
-
Ubuntu 26.04 Beta Arrives with Some Surprises
Ubuntu 26.04 is almost here, but the beta version has been released, and it might surprise some people.
-
Ubuntu MATE Dev Leaving After 12 years
Martin Wimpress, the maintainer of Ubuntu MATE, is now searching for his successor. Are you the next in line?
-
Kali Linux Waxes Nostalgic with BackTrack Mode
For those who've used Kali Linux since its inception, the changes with the new release are sure to put a smile on your face.
-
Gnome 50 Smooths Out NVIDIA GPU Issues
Gamers rejoice, your favorite pastime just got better with Gnome 50 and NVIDIA GPUs.
-
System76 Retools Thelio Desktop
The new Thelio Mira has landed with improved performance, repairability, and front-facing ports alongside a high-quality tempered glass facade.
-
Some Linux Distros Skirt Age Verification Laws
After California introduced an age verification law recently, open source operating system developers have had to get creative with how they deal with it.
-
UN Creates Open Source Portal
In a quest to strengthen open source collaboration, the United Nations Office of Information and Communications Technology has created a new portal.
-
Latest Linux Kernel RC Contains Changes Galore
Linux kernel 7.0-rc3 includes more changes than have been made in a single release in recent history.
-
Nitrux 6.0 Now Ready to Rock Your World
The latest iteration of the Debian-based distribution includes all kinds of newness.
-
Linux Foundation Reports that Open Source Delivers Better ROI
In a report that may surprise no one in the Linux community, the Linux Foundation found that businesses are finding a 5X return on investment with open source software.