WebHTTrack Website Copier
Grabbing Websites with WebHTTrack
ByWebHTTrack backs up complete websites for offline access and modifies the links automatically.
Despite ubiquitous Internet access, users often have good reason to create offline copies of websites – be it for archiving or to provide the content on your intranet. However, manual mirroring can be time-consuming and cumbersome. Tools like WebHTTrack can help, and they allow convenient updating of the content.
On our lab machine with Linux Mint 12, the installation was easy. I typed
sudo apt-get install httrack webhttrack
to install the packages and dependencies. The program website offers packages for Debian, Ubuntu, Gentoo, Red Hat, Mandriva, Fedora, and FreeBSD, and versions are also available for Windows and Mac OS X. Each package contains a command-line variant called HTTrack (useful for scripting) and a graphical interface called WebHTTrack (or WinHTTrack on Windows).
Always at Your Service
To launch the interface, either find it directly through the Applications menu or simply type webhttrack at the command line to launch a local web server on port 8080, open the default browser, and load a graphical wizard that guides you through the process (Figure 1).
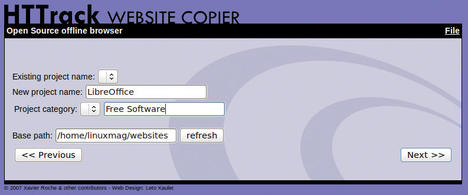
To download websites, you first need to define a project name and an associated category or select an existing entry. The tool lists stored sites in groups, which is useful, in particular in large archives, because it helps you keep track of your downloads. You can tell WebHTTrack where to create this archive by defining the Base path; appropriate subdirectories are created automatically.

On the next page, enter the website to be mirrored; I’m using the Document Foundation website as an example. The relevant addresses can either be typed directly in the appropriate fields, or you can point to a text file with one URL per line. The tool supports FTP, HTTP, and HTTPS addresses, for which you can either enter a complete path (e.g., http://www.documentfoundation.org) or restrict to individual subdirectories (e.g., http://www.documentfoundation.org/foundation/). Password-protected pages are best added by clicking the Add a URL button.
Attention to Detail
WebHTTrack offers several modes for downloading the source content. Automatic Website Copy runs without asking you any questions, whereas Website Copy Prompt is more verbose and asks you questions if in doubt. Load special files lets you secure individual files without following the links they contain, and Branch to all links is useful for saving bookmarks because it saves all the links on the first page in each case. In contrast, Test links on pages doesn’t download anything, but only checks whether links are valid.
Hiding behind the inconspicuous Settings button are numerous options that let you set up almost every detail. Among other things, you can specify the order in which the files are loaded. Also, you can configure the way in which WebHTTrack stores the documents locally in Build (Figure 2).
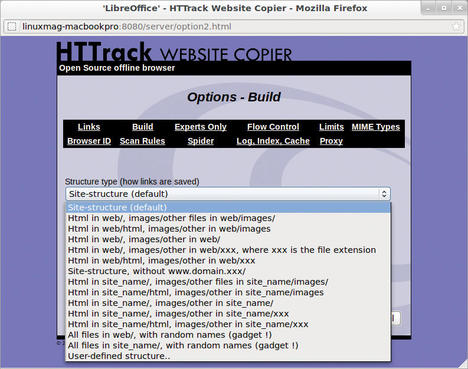
By default, the directory structure is mirrored 1:1 in the corresponding subdirectories, but you can also choose to structure by file type – for example, to keep images and PDF files separate. If the given structures are insufficient, you can simply enter custom paths based on variables. WebHHTrack takes care of rewriting links, and it removes error pages or passwords on request.
Depending on the available bandwidth, you might want to use Flow Control and customize the number of simultaneous connections, as well as the timeouts and retries in the event of an error. These settings help back up slow servers without exposing them to excessive access attempts.
As a kind of built-in airbag, you can set Limits for the overall size, the transfer rate, and the transfer time. Further settings, primarily intended for advanced users, are available in the MIME Types, Browser ID, Spider, and Log, Index, Cache tabs. In some networks, the use of a Proxy can be relevant.
Filtering
The Scan Rules are a powerful feature that lets you specify the desired content precisely. By default, all pages below the specified URL, including the links they contain, are backed up. But on the LibreOffice website, for example, which also contains download links, this would mean that, in addition to the actual homepage, numerous program files would also be grabbed. To specify more precisely what you want to download – and what you want checked for links – you can define filters.
For example, to download all links, except those that point to PDF files, you would filter for -*.pdf. However, to exclude PDFs on the Document Foundation site only, you need the rule -www.documentfoundation.org/*.pdf. Similarly, -www.documentfoundation.org/themes/*.css skips not only all CSS files, but also the images to which they link.
Instead of providing a negative list, you can define a positive list to designate explicitly the content to be backed up; for example, -* +*.htm* +www.documentfoundation.org/*.pdf only grabs PDF documents published on the Document Foundation homepage.
The preliminary -* excludes all types not specifically listed; however, to parse the individual pages for links, you additionally need to specify +*.htm*. Filters are processed from left to right; the element listed last has the highest priority. A rule such as -* +www.documentfoundation.org/*.htm* -www.documentfoundation.org/*.html5 loads links to .htm and .html but not to .html5. WebHTTrack is intelligent and rewrites links to files that have not been downloaded so they can be linked directly online. For example, if you exclude the PDFs from the download, a click on the appropriate link takes you to the online version, so this solution is ideal for documents that are updated frequently. Filters also can help set size limits. For example, -*.zip[>1024] -*.pdf[<2048] stipulates that no links to ZIP files larger than 1MB are downloaded, and no links to PDFs unless they are larger than 2MB. The parameters can also be combined; for example, -*.png[<5>100] only allows PNG files between 5 and 100KB, and thus excludes both thumbnails and large images. For experts, WebHTTrack offers the possibility of selecting by MIME type and using regular expressions to refine the filters.
Off You Go!
After configuring the addresses, filters, and other options, you can finally click on Start >> to tell WebHTTrack to begin the download. Depending on the scope and complexity of the site, this process takes a while to complete; a status window (Figure 3) keeps you posted on the progress.
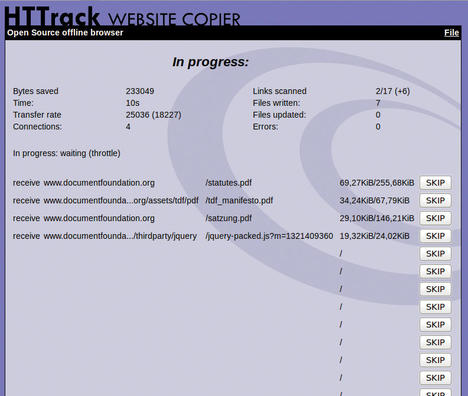
The program will follow each link to the specified addresses, download the desired content according to the filters, and write the files. According to the authors, sites with Flash content, CGI scripts, Java applets, and JavaScript are problematic because they cannot always be analyzed easily. If possible, WebHTTrack will try to identify the file type and rename accordingly (e.g., content management systems that often use PHP URLs to serve up regular HTML files).
After the tool has completed its work (Figure 4), the wizard offers to show you the logfile to verify that everything has worked – any errors, non-existent files, and other problems will be listed there.
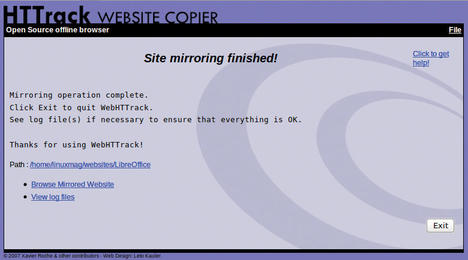
For an overview of all locally mirrored pages, check out the index.html file in the root directory – the previously mentioned categories come back into the game at this point, because they provide the structure for the archive (Figure 5).
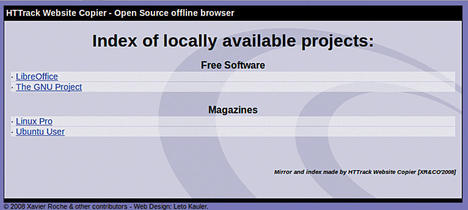
In addition to one-off downloads, WebHTTrack also supports updates of previously loaded content. To this end, it creates a local cache and tries, when you select the * Update existing download mode to load only files that have changed since the last run. Elements that no longer exist on the server are deleted; however, you can choose the appropriate options to disable this function.
Back to the Roots
WebHTTrack is, in principle, only a graphical front end for the actual workhorse, a command-line program called HTTrack that is particularly amenable to scripting. All of the options the wizard provides are available as parameters, as the extensive online documentation shows. For example,
httrack http://www.documentfoundation.org -* +*.htm* +*.pdf -O /home/floeff/websites
loads all of the PDF files from the Document Foundation website in a subdirectory. Additionally, the command-line version lets you run an external command after each file you download – for example, to enter the results to a database or create checksums.
Conclusions
WebHTTrack provides a convenient approach to downloading entire websites for offline browsing. The clear-cut wizard offers functions that can help users customize the download. However, downloading online content is not as trivial as you might first think – external links, dynamic pages, and numerous links quickly turn this into a Herculean task.
With a little background knowledge, you can work around the biggest hurdles – but reading the FAQ, the command-line documentation, and, in particular, the scan rules is something you can’t avoid.
Info
[1] Appropriate use
next page » 1 2 3
Subscribe to our Linux Newsletters
Find Linux and Open Source Jobs
Subscribe to our ADMIN Newsletters
Support Our Work
Linux Magazine content is made possible with support from readers like you. Please consider contributing when you’ve found an article to be beneficial.

News
-
Gnome’s Dash to Panel Extension Gets a Massive Update
If you're a fan of the Gnome Dash to Panel extension, you'll be thrilled to hear that a new version has been released with a dock mode.
-
Blender App Makes it to the Big Screen
The animated film "Flow" won the Oscar for Best Animated Feature at the 97th Academy Awards held on March 2, 2025 and Blender was a part of it.
-
Linux Mint Retools the Cinnamon App Launcher
The developers of Linux Mint are working on an improved Cinnamon App Launcher with a better, more accessible UI.
-
New Linux Tool for Security Issues
Seal Security is launching a new solution to automate fixing Linux vulnerabilities.
-
Ubuntu 25.04 Coming Soon
Ubuntu 25.04 (Plucky Puffin) has been given an April release date with many notable updates.
-
Gnome Developers Consider Dropping RPM Support
In a move that might shock a lot of users, the Gnome development team has proposed the idea of going straight up Flatpak.
-
openSUSE Tumbleweed Ditches AppArmor for SELinux
If you're an openSUSE Tumbleweed user, you can expect a major change to the distribution.
-
Plasma 6.3 Now Available
Plasma desktop v6.3 has a couple of pretty nifty tricks up its sleeve.
-
LibreOffice 25.2 Has Arrived
If you've been hoping for a release that offers more UI customizations, you're in for a treat.
-
TuxCare Has a Big AlmaLinux 9 Announcement in Store
TuxCare announced it has successfully completed a Security Technical Implementation Guide for AlmaLinux OS 9.